




AWS has just made a new open-source tool called Karpenter generally available. I will dig into how it works, and will be unavoidably comparing it with what we at CAST AI have built.
What exactly is Karpenter, how does its autoscaling mechanism work, and should you use it?
Karpenter is a very simple autoscaler with two reactive policies. Its biggest selling point? No node pools.
Let’s take a look at how Karpenter works and compare it to the autoscaling mechanisms of CAST AI.
Quick feature comparison - CAST AI vs. Karpenter
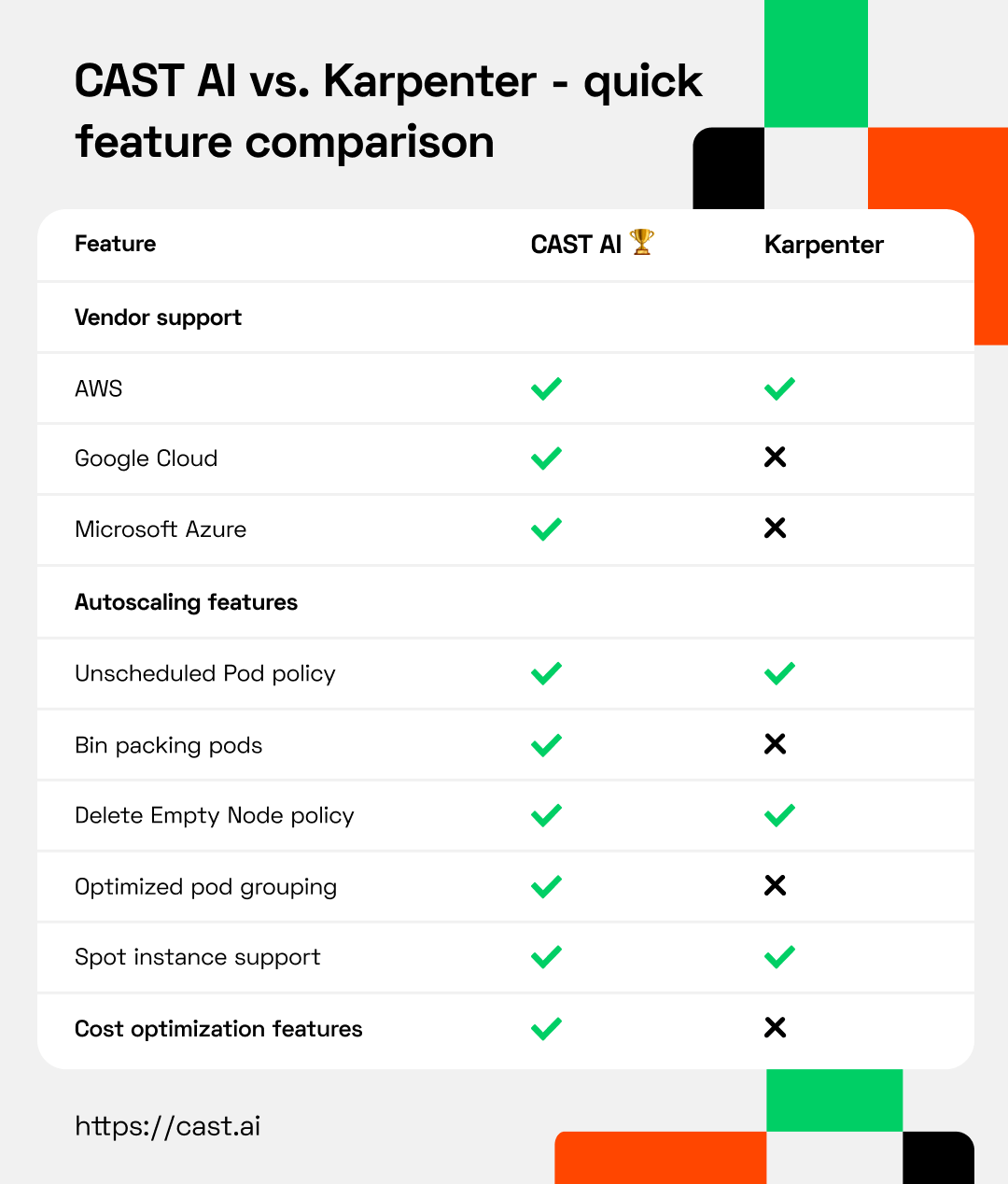
Detailed feature comparison of Karpenter and CAST AI
- Installation and onboarding
- Autoscaling policies
- Cloud vendor support
- No node pools
- Pod grouping
- Cost optimization
- Karpenter vs. CAST AI - which autoscaler is a better pick for you?
Installation and onboarding
After trying Karpenter out, I’d say that onboarding isn’t trivial but not as hard as the Kubernetes Cluster Autoscaler.
Karpenter onboarding requires you to have eksctl CLI installed and configured, even if you created an EKS cluster without the help of eksctl. It takes around 6 to 7 steps to get started with Karpenter
CAST AI doesn’t have a eksctl dependency and you’re looking at a 2 steps process that your IT manager could complete on his own in a minute or two.
Autoscaling policies
Karpenter has only two most basic autoscaling policies. At first glance they are quite similar to two of the policies in CAST AI (Unscheduled Pod Policy and Node Deletion policy). Let’s compare the two.
1. Provisioner
At its simplest form without sub features CAST AI’s Unscheduled Pod Policy works in a similar way as Karpenter’s Provisioner.
If there are pods that can’t start because no suitable node has been found by Kubernetes vanilla scheduler - a new node will be created based on those pending pod constraints like zone, subnet, PodAntiAffinity, capacity preference (spot or on-demand).
Karpenter has these constraints available for NodeSelector, NodeAffinity, TopologySpreadConstraints:
requirements:
- key: node.k8s.aws/instance-type #If not included, all instance types are considered
operator: In
values: ["m5.large", "m5.2xlarge"]
- key: "topology.kubernetes.io/zone" #If not included, all zones are considered
operator: In
values: ["us-east-1a", "us-east-1b"]
- key: "kubernetes.io/arch" #If not included, all architectures are considered
values: ["arm64", "amd64"]
- key: " karpenter.sh/capacity-type" #If not included, the webhook for the AWS cloud provider will default to on-demand
operator: In
values: ["spot", "on-demand"]
Karpenter supports GPU and ARM with the following tolerations: nvidia.com/gpu, amd.com/gpu, and aws.amazon.com/neuron. To add a GPU node, one needs to define a specific list of nodes (and we’re back to the node pool idea).
CAST AI allows you to specify more pod constraints, like get me instances with fast local storage for Spark jobs, but does not require you to specify the instance types yourself. In case you didn’t check lately, there are 475 available types on AWS which makes it easy getting back to implicit NodePools by accident.
You can also specify the Spot interruption rate per cluster and override per workload in CAST AI. For example you may want your casual Spot workload in a cluster to be on more cost efficient Spot instances even if that means these instances could be interrupted once in a while.
But those huge Jupyter notebook pods with a ton of resources? You want them to run Spot Instances that are so unpopular that they barely get ever interrupted.
Back to the Node Pools against own will
Running your Kubernetes workloads on burstable T3a Instance types is a crime to your business and your DevOps, but this is what you will get by default with Karpenter. Because, as you guessed it, they are the most affordable instances.
Don’t want burstable instances? Then list all acceptable Instance types in Karpenter Provisioner CRD which you want in your Kubernetes cluster to have. And with that you have just specified a cherry picked Node list and are implicitly back to NodePools.
And what if these cherry picked Node lists are not available during Black Friday or Xmas days? You will need to extend the list with more alternatives. Many more alternatives. But didn't the first paragraph in this article say there will be no Node Pools? Unfortunately they are unavoidable with Karpenter under the hood.
2. Delete Empty Node policy
As the name implies, Karpenter can and will delete empty nodes. This policy allows you to set the Time To Live for empty nodes (ttlSecondsAfterEmpty with a default of 30). CAST AI’s Delete Node policy works in the same fashion. CAST AI engine will not remove nodes if there are workloads running on them (excluding DaemonSets of course).
Kubernetes scheduler by default acts in a very fair way and will always distribute workloads for maximum performance and availability. And if you’re running EKS you can’t change the Kubernetes scheduler profile.
Let’s look at this with an analogy
Imagine a train (Kubernetes cluster) with 10 train cars (Nodes), each train car can seat 100 passengers (pods), the train has a capacity to transport 1000 passengers at peak.
The train moves from the central station fully utilized with 1000 seats taken and with every stop more people get off the train than on it. Even a few stops before the end of the train journey, if the train is carrying only 15 passengers out of 1000, someone needs to make sure that there are empty train cars. It’s likely that there are 1 to 2 passengers in a train car enjoying their privacy and the Delete Empty Node train car can’t find anything to remove.
So how does Karpenter help with over provisioned resources for off peak times when load is lower?
Enter Node Expiry
Karpenter offers a Node Expiry feature. If a node expiry time-to-live value (ttlSecondsUntilExpired) is reached, that node is drained of pods and Node is deleted.
Great! But wait a minute, what about your workloads that are running on these nodes? Sorry, end of shift. Nodes are going down, say hello to downtime.
Alright, but how would you know what the expiration time should be? If you get it too short, your pods are going down, you then have to wait several minutes for the Karpenter provisioner to add new nodes with refreshed ttlSecondsUntilExpired.
If you set ttlSecondsUntilExpired too long, you’re wasting your money. In other words Karpenter reacts in time to add new capacity so your cloud bill could expand, but leave you hanging with reducing that excess capacity.
CAST AI, on the other hand, offers Evictor that shrinks the cluster to the minimum number of nodes by bin packing pods (simulating evictions, honoring Pod Disruption Budgets etc). Once Evictor makes a node empty, it’s deleted automatically.
Cloud vendor support
At the moment, Karpenter only supports AWS. The code has a lot of AWS-specific hardcoded logic. For instance using EC2 Fleet and Spot Fleet, without a way forward for other clouds. Karpenter has fake interfaces created in the code so the project looks pluggable and open enough if someone were to take the initiative to enable other cloud support in Karpenter.
CAST AI supports AWS (EKS, kOps), Google Cloud Platform (GKE), and Microsoft Azure (AKS).
No node pools
The promise of being free of node pools sounds great. But Karpenter doesn’t offer users almost any control over the scheduling decisions when using a “naked” Provisioner.
A Provisioner is Karpenter’s Kubernetes CRD which defines the node creation constraints. For example, if you had workloads that needed a GPU and you wanted the GPU nodes to have a taint (so that only the pods that actually need it are placed on those nodes), you would create a Provisioner like that:
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: gpu
spec:
requirements:
- key: node.kubernetes.io/instance-type
operator: In
values:
- p3.2xlarge
- p3.8xlarge
- p3.16xlarge
taints:
- key: nvidia.com/gpu
value: true
effect: “NoSchedule”
In Karpenter, the engineer still needs to have deep knowledge of the available instance types with all of their nuances.
To use the SSDs in a K8s cluster, you would need to create a user-data script that makes a single logical disk out of those local SSDs and creates a symbolic link for the kubelet to use. That requires creating an EC2 Launch Template and referencing it in the Provisioner resource. And, most importantly, you need to keep it up to date if you want to achieve cost savings.
Conclusion: In more complicated clusters, you’d have to create many different Provisioners, i.e. node pools: one for GPUs, another one for storage optimized, yet another one for infrequently interrupted Spot instances, etc.
Provisioner conflicts
When there are multiple Provisioner resources defined and an unschedulable pod can tolerate/select any of them, the result will be non-deterministic.
Here’s an example:
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: team-a
spec:
labels:
team: a
requirements:
- key: "node.kubernetes.io/instance-type"
operator: In
values: ["m5.large"]
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: team-b
spec:
labels:
team: b
requirements:
- key: "node.kubernetes.io/instance-type"
operator: In
values: ["m5.2xlarge"]
apiVersion: v1
kind: Pod
metadata:
name: pod
spec:
containers:
- image: nginx
name: pod
The nginx pod would be scheduled on either the m5.large or the m5.2xlarge node (chosen based on the sequence the API-Server returns for the records). This is another dimension that the DevOps engineer would need to think about.
The Provisioners should clearly define constraints, and all pods should clearly define the selectors to reduce or eliminate randomness.
In CAST AI, the selectors/tolerations are predefined, and engineers don’t have to come up with them on their own.
Pod grouping (a.k.a. Bin Packing on provisioning)
Karpenter's GitHub states that they use bin packing, but only in the nodePlacer sense. That is, grouping pods to be placed on nodes to avoid creating a separate node for each pod.
In CAST AI we use Permutations and Clique functions. Their purpose is to find out the most optimal pod groupings.
Karpenter doesn’t have elaborate algorithms to group pods optimally. The algorithm used is basically creating a hash of the pod constraints. This means that otherwise compatible pods will end up on different nodes (Karpenter will create multiple nodes).
Consider this example:
apiVersion: v1
kind: Pod
metadata:
name: pod1
spec:
nodeSelector:
topology.kubernetes.io/zone: "eu-central-1a"
containers:
- image: nginx
name: pod
apiVersion: v1
kind: Pod
metadata:
name: pod1
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- "eu-central-1a"
- "eu-central-1b"
containers:
- image: nginx
name: pod
Even though the pods could fit into a single node placed in the eu-central-1a zone, Karpenter will create two nodes (that might even end up in the same zone) because the hash of the pod constraints is different. Your Cluster has overprovisioned capacity, and Karpenter leaves you without a way to shrink it.
Cost optimization
When Karpenter bin-packs pods, it produces a list of viable instance types per each pod group. For example, if there’s a pod group that needs 2 CPU and 8 GiB, then a list of all instance types that have at least 2 CPU and 8 GiB is retrieved. The list is sorted by resource weight.
Karpenter sorts those instance types using a weight function where 1 CPU = 1 GiB, favoring nodes with higher CPU and lower memory:
// weightOf uses a euclidean distance function to compare the instance types.
// Units are normalized such that 1cpu = 1gb mem. Additionally, accelerators
// carry an arbitrarily large weight such that they will dominate the priority,
// but if equal, will still fall back to the weight of other dimensions.
func weightOf(instanceType cloudprovider.InstanceType) float64 {
return euclidean(
float64(instanceType.CPU().Value()),
float64(instanceType.Memory().ScaledValue(resource.Giga)), // 1 gb = 1 cpu
float64(instanceType.NvidiaGPUs().Value())1000, // Heavily weigh gpus x 1000
float64(instanceType.AMDGPUs().Value())1000, // Heavily weigh gpus x 1000
float64(instanceType.AWSNeurons().Value())*1000, // Heavily weigh neurons x 1000
)
}
After sorting, only the first 20 of the nodes are picked.
This list might not contain the cheapest instance types because of Karpenter’s particular weighing system. There is no inventory database that can tell exactly how much something costs.
After the bin-packing and sorting, the list is passed to the EC2 Fleet API. The mode of choosing the instance type depends on whether it’s an on-demand node or spot instance.
On-demand instances
In this case, Karpenter passes the “lowest cost” allocation method that makes the EC2 Fleet API choose the cheapest instance type out of the 20 received viable instance types. There might be cheaper instance types, but the API works with what it was given.
Spot instances
Karpenter passes the “capacity optimized prioritized” allocation method that makes the EC2 Fleet API choose the instance types which have the highest availability, prioritizing the instance types at the top of the list. This has nothing to do with cost optimization and could be considered something similar to the CAST AI “Least interrupted” Spot reliability setting.
CAST AI offers an entirely different approach to cost optimization. The platform selects the most cost-efficient instances that match the workload requirements and automatically rightsizes instances to avoid overallocation. CAST AI also comes with features such as cost reporting on any level, information about cluster cost, or potential savings. Karpenter doesn't have any of those.
Karpenter vs. CAST AI - which autoscaler is a better pick for you?
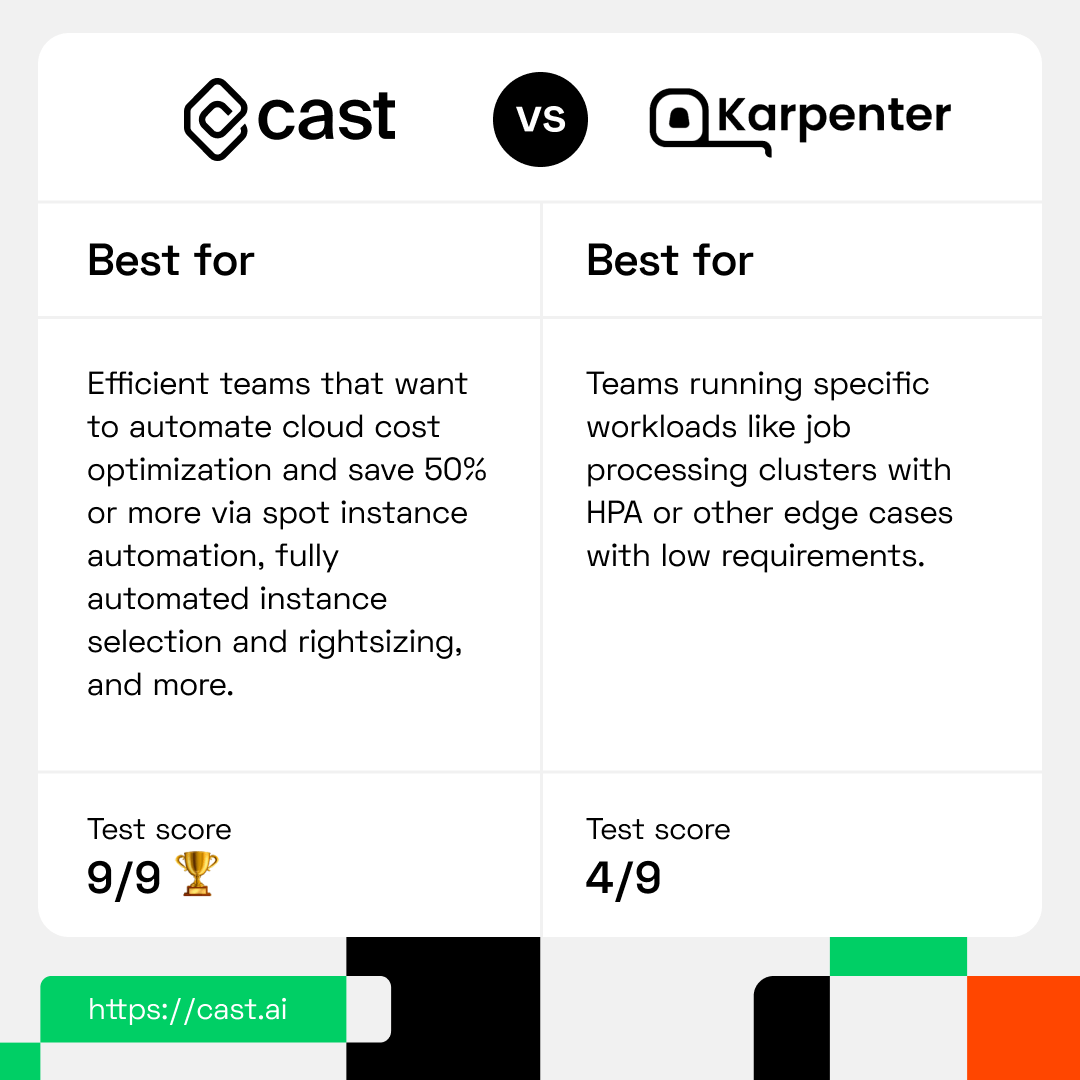
As you can see, Karpenter offers a limited set of functionalities right now.
AWS Karpenter is an option if you’re on AWS and considering the native Kubernetes Cluster Autoscaler. Today, AWS offers 400+ instances, so node pools on which the Kubernetes Cluster Autoscaler works become unmanageable considering the exhaustible instance inventory. This is essentially what Karpenter kind of tries to solve.
If you’re looking for an autoscaler that can significantly reduce your cloud bill for production workloads without impacting their availability, you need to look elsewhere.
CAST AI offers a substantially more robust set of features which makes it a great fit for reliable automated cost reduction on production and development workloads. It also works with all three major cloud providers: AWS, Google Cloud, and Azure.
To see what results could CAST AI bring you, you can register and start with a free cluster analysis or book a quick demo by clicking the button below.